光互連與光交換解鎖超節點規模上限|曦智科技CTO孟懷宇博士報告回顧
在智猩猩聯合主辦的2025中國AI算力大會同期進行的「超節點技術研討會」上,曦智科技聯合創始人兼首席技術官孟懷宇博士圍繞《光互連、光交換:解鎖超節點規模上限》發表了主題報告。
孟懷宇博士指出,超節點技術在大模型的訓練與推理過程中發揮著至關重要的作用。其理想架構為單層拓撲,這能夠顯著降低延遲與成本。然而,由于國產芯片制程的限制,往往需要集成數百塊國產GPU才能與海外產品相當。
在這種情況下,孟懷宇博士認為,擴大超節點規模主要有兩條路徑:一是提升單機柜的功耗,二是增加機柜的數量。而跨機柜互連必然要依賴光技術。
針對光互連大規模應用所面臨的功耗、成本以及可靠性挑戰,孟懷宇博士認為高集成光學方案是破局的關鍵。通過采用共封裝光學(CPO)技術,將光電轉換集成至芯片附近,可將功耗降低 1/3 至 2/3,同時也減少了分立器件的數量,從而提升了可靠性。
最后,孟懷宇博士還分享了曦智科技的分布式光交換(dOCS)技術。dOCS在光I/O層嵌入交換功能,實現了兩大價值:一是動態冗余,在故障發生時,能夠以服務器為單位切換拓撲,從而降低備份成本;二是靈活伸縮超節點規模,可根據不同模型的算力需求進行適配。最終,曦智科技希望構建一個融合光電計算、光互連與光交換的高效集群。
本文為孟懷宇博士的報告實錄,有一定刪減。
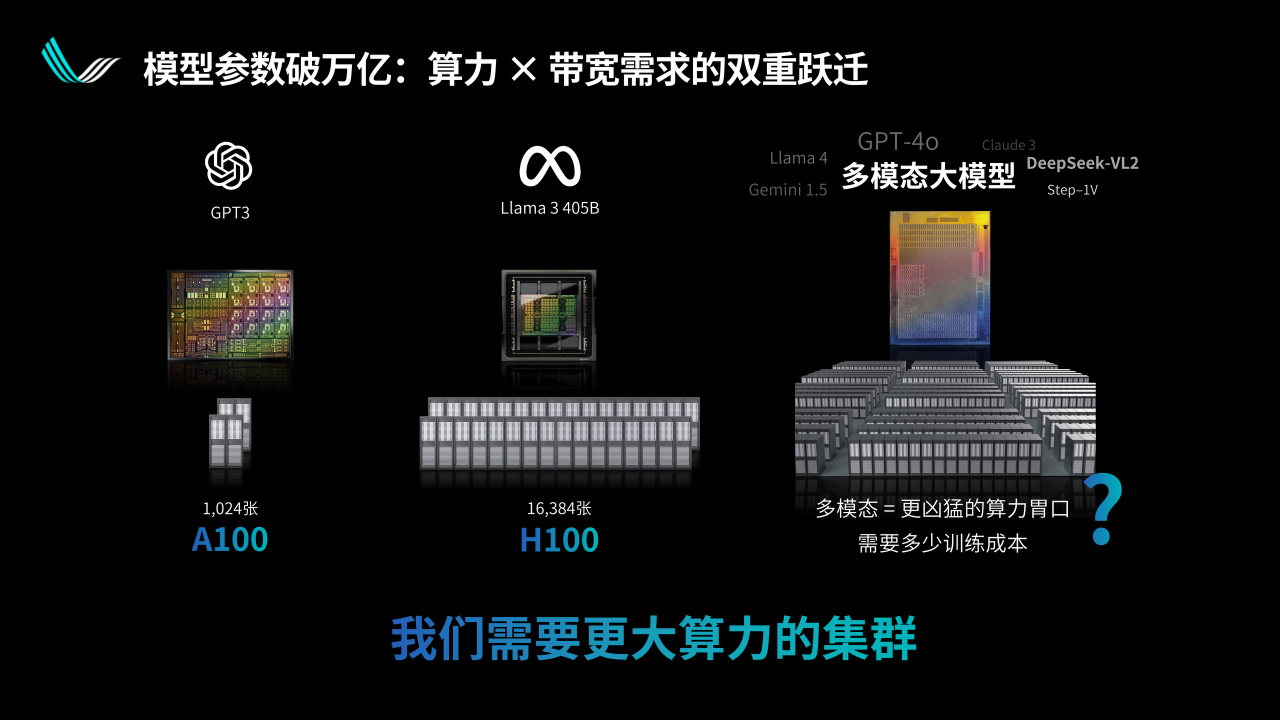
超節點本身的價值我覺得不需要過多的說,今天前面各位專家已經也談到了很多,主要是在大模型訓練和推理兩個層面。
在訓練層面,我們看到模型的尺寸自從GPT-3出來以后迅速發展,訓練所需要的GPU數量也指數級增長。超節點可以極大地提高訓練的效率,尤其是對比較大的模型。
推理可能是2025年以來在國內市場更受關注的一個應用場景。
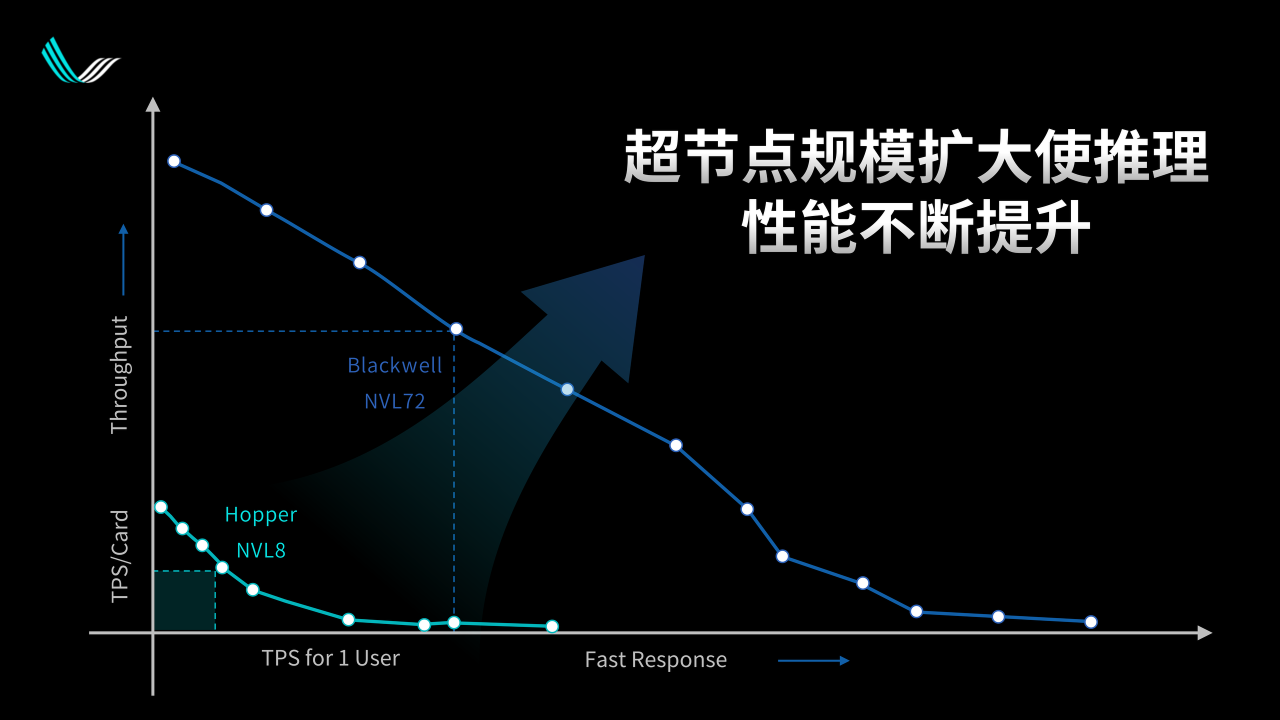
上面這張圖是黃仁勛在25年上半年GTC上展示的一個圖片的簡化版本,意思是說大模型的推理可以按照橫軸和縱軸分成兩個部分。橫軸是單個用戶輸出token的速度,可以把它翻譯成用戶體驗,從某種意義上也可以把它翻譯成價格。而縱軸是每張卡可以輸出的模型數量,從經濟學的邏輯來說可以把它翻譯成產量。那么價格乘以產量就是總的產值。
因此我們在這張圖片上面選一個運營點的時候,它所囊括的那個方塊,就意味著這個狀態下系統可以產生的價值。黃仁勛在GTC上想要展示的,是他們的Blackwell NVL72超節點從產生價值的角度來講遠遠高于之前的8卡集群。
01 超節點架構應往單層發展

超節點的架構我們看到有單層超節點和兩層超節點兩個邏輯,這個概念也很清楚,就是超節點的計算卡需要多少層交換機才能夠組成一個整體。
從算法的應用上來講,尤其是超節點的推理來說,我們希望它整體延遲更低、成本更低、可靠性更好。由此推得,超節點最好是只有一層。但是現實中我們可能沒有足夠大的交換機,沒有足夠大的高效互連,使得在某些情況下沒辦法把超節點做成一層架構。也有超節點是用兩層的架構,但是我們覺得這應該是暫時的一個妥協方案,最終超節點架構應該往單層方向發展。

剛才說了,超節點我們希望是單層,這是一個點。第二個點,在國產生態中,單卡單芯片算力是嚴重受限的,基本上直接被制程所限制。那么,當國產芯片制程可能一段時間內停留在7納米水平的時候,我們的單芯片的算力、帶寬、顯存容量、顯存帶寬,比現在主流的NVL72用的B200芯片,基本上是2倍、4倍甚至7倍的差距。
如果人家一個超節點NVL72有72個B200芯片,咱們假設使用7nm國產GPU,大概也就是A100的水平,基本上就是幾百張卡。
剛才提到我們希望超節點是一層的,然后又希望國產超節點要對標海外的的超節點,這樣就得到我們需要幾百個國產GPU連成一層的超節點,我們要怎么實現呢?
02 單層超節點擴大規模主流路徑

我們覺得現在的起點和將來的終點,應該都是大家比較認可的。短期內盡量往單個機柜塞,單機柜的功耗上限有多少就塞多少。比如傳統數據中心里,非計算、非高電的機柜功耗就是20kW,可能還不到。將來每個機柜可能會超過100kW,甚至我也看到有更多的一些規劃,我們肯定也希望機柜的數量盡量多。因為國產GPU,100kW放進去可能也就是100個,如果需要幾百張卡的超節點的話,肯定是需要多個機柜的。
所以我覺得發展的起點和終點大家應該是有共識的:起點是單機柜,終點是多機柜,且每個機柜的電量會越來越高。
從機柜數量和每個機柜能夠容納的GPU數量來講,可以說有兩條路徑。第一條路徑是先把單個機柜的功耗往上提,盡量往里塞(GPU),看能塞多少。NVIDIA走的其實就是這樣一個路線,今年也發布了后面的幾代產品,從NVL72、144到576。還有一條路徑是先考慮增加機柜的數量,把數量加到位了之后,再把他們連成一個超節點。海外比較典型的樣品就是谷歌的TPU,最新應該是有數千卡的超節點,它其實就是一個多機柜的展示方法。
這時出現了光互連的必然性。當超過一個機柜,多個機柜的GPU互連的時候,直接使用光可能是一個必要的選擇。

超節點GPU直接出光使用多個機柜的時候有什么好處呢?
首先,光纜相對于銅纜最明確的優勢就是距離遠。一般來說,銅纜112G可以走1米或者2米,或者AEC有的時候可以走3-7米。而普通的短距光纜很容易就可以到50米、100米甚至千米級別。距離不是問題,這其實就產生了很多的可能性,比如組成超節點的機器可以隨便放在哪里。
今天上午,包括之前的專家也提到高電機柜本身也是有相當的技術挑戰的。比如整個數據中心的土建、供電、液冷以及整套系統如何設計等。當我們有跨機柜的超節點能力的時候,短期內其實就可以規避這些問題。
比如同樣是四個服務器的超節點,假設單個機柜無法支持那么大的供電和散熱,我們可以把它們放在兩個機柜里,通過光纜互連,這樣就能組成一個超節點。
解鎖了距離限制之后,其實還有很多其他的優勢。從商業上來講,交付形態不一定就是完整的機柜,因為超節點本身就是多個服務器連起來,我們可以用4個、6個或者8個服務器,也可以按照客戶的需求靈活配置,對有些客戶來說他們是比較在意這一點的。
大家都知道光纜傳輸距離遠遠長于銅纜,另外還有一點可能大家沒太意識到,光纜其實比銅纜要細很多。
上圖右側展示的是我們已經部署落地的光纜和銅纜混合的一個超節點。大家很容易看出來,淺藍色很細的線就是光纜,占據了圖片很大面積的黑色的線就是銅纜,很明顯他們的尺寸是不一樣的。
如果用銅纜來做這件事,可能上架的時候會阻塞風道,影響散熱,導致產生一些問題。當然也可以用液冷,但是液冷又是另外一層技術難點。另外銅纜比較重,會去拉上面的銅纜接口。銅攬接口長期承重的時候,會有可靠性的問題。這些都是我們在現實部署中遇到的一些具體情況。

使用光纜業界也有一些顧慮,包括功耗、成本和可靠性三個方面,尤其是在大規模超節點中,光纜的使用數量會非常大。一個典型的例子就是華為今年發布的CloudMatrix 384超節點。
上圖我圈出了兩個數字,CloudMatrix 384在二層使用了3000多根光纜,也就意味著6000多個光模塊。這么大數量的光模塊顯然對于功耗、成本和可靠性有著非常高的要求。
為什么光互連相比銅互連會有這樣的問題呢?基于可插拔光模塊的光互連,實際上不是半導體產品,每個光模塊至少有二三十個零件。激光器、隔離器、棱鏡等,還要用膠水等各種各樣的方式把它們粘起來,之后以上這些再乘以4或者乘以8。所以每個光模塊里都有幾十個分立的零件,通過機械的方式組合成最終的產品。
大家很容易聯想到,我們可以把光模塊這樣的非半導體產品變成半導體產品,把這些元器件全部或者盡量多的集成到1個或者2個芯片里,從而符合長期以來大家認知當中的芯片產品的邏輯。
芯片產品不怕復雜,一個計算芯片可能有數十億個晶體管,只要能夠在半導體工藝中進行生產,其可靠性就會非常好。在需求量非常大的時候,每個芯片的成本也可以降低到可控層面。因此,我們覺得解決以上問題很重要的一個方向就是使用集成度更高、更接近于半導體邏輯的光學產品。
03 光互連技術的演進
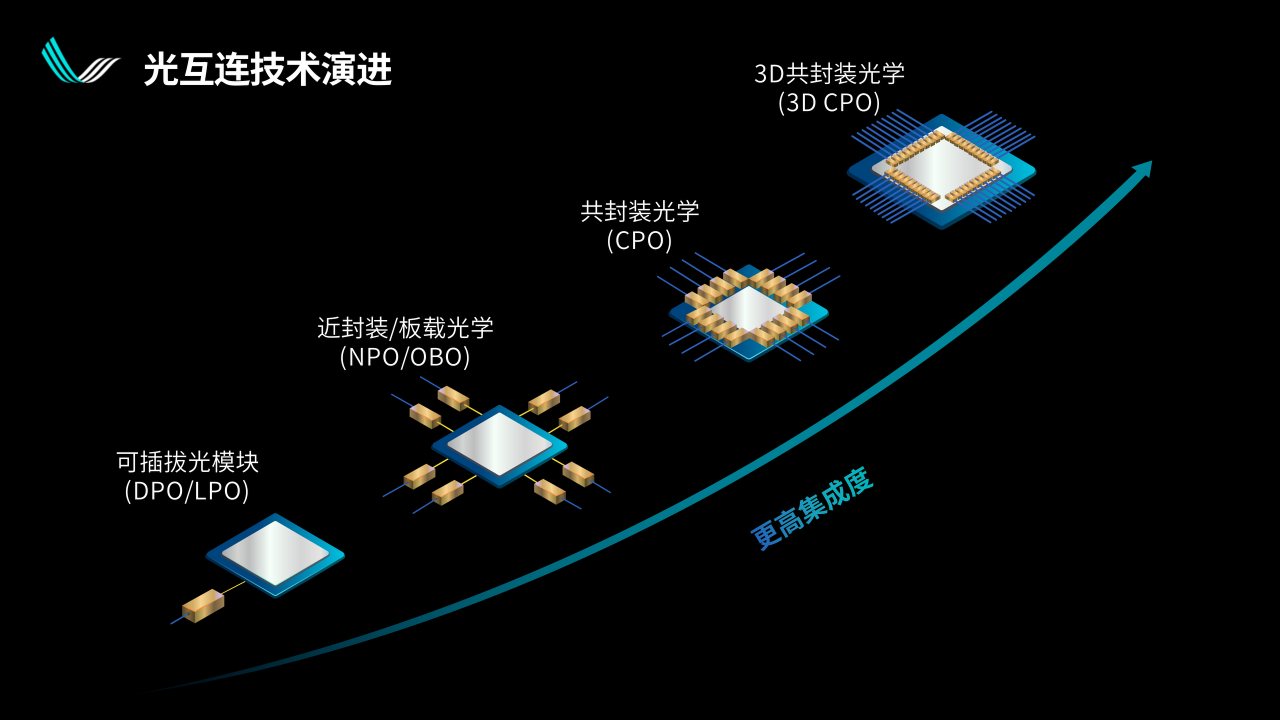
通過這張圖我們可以看到光互連技術的演進路線。
左下角是目前大部分光通信的狀態,業界在這方面也有幾十年的經驗,是一個可插拔的光模塊。光模塊距離主芯片的距離,從服務器的尺寸來看可能有幾十厘米。再進一步,可以把光電轉換模塊放在離主芯片更近的地方,比如放在同一個PCB板上,這個距離可能會到5cm、3cm。
再往后可以放在同一個封裝上面,變成所謂的共封裝光學Co - Packaged Optics,簡稱CPO,這也是最近兩年以來比較火的一個概念。
最后我們很容易想象,可以把光電轉換和主芯片,也就是數字芯片垂直3D堆疊放在同一個芯片上,實現光電融合。

這樣的技術演進在集成度上有多大的好處呢?這里有一個直觀的展示。
上面中間展示的是博通51.2T的TH5交換機,也是博通第一代量產化的共封裝光學CPO產品。大家可以看到中間的封裝旁邊有四塊玻璃窗口一樣的東西,里面是可以傳達51.2T的一個光電轉換引擎,被封裝在芯片邊里。
如果51.2T的帶寬用傳統的光模塊來支持,會是什么狀態呢?那就是周圍這一圈光模塊,128個光模塊全部擺在一起就是這個樣子。
通過上圖,這樣大家可以很直觀的看到兩種技術在集成度上會有多大的提升。

功耗層面,從光學層面來講,共封裝光學相比傳統可插拔光模塊會節省1/3-2/3左右的功耗。功耗相對來說是小一點的擔憂,畢竟不管怎么說,通信的功耗相比1kW以上的GPU來說可能還是很小的。
可靠性是更為重要的一點。集群在做訓練和推理的時候,與傳統的網絡邏輯不一樣,他們是協同作戰。也就是說假如一個GPU因為互連出現問題,少則拖累一個服務器,多則整個萬卡集群需要重啟,這個代價是非常大的。所以業界對于集群任何部分的可靠性都有很高的要求,當然也包括對互連的可靠性。
我們使用更先進的集成光學技術的時候,對于光互連的可靠性實際上也有比較客觀的提升,最簡單的就是分立器件的數量少了。當然每個器件通過機械的方式安裝在一起的時候,每一個安裝的地方都有可能出問題。此外因為是光互連,某一個地方進去一粒灰塵可能都會產生問題,我們可以盡量減少灰塵可能進去的地方,從而降低出現問題的概率,包括把激光光源拉到面板上面遠離熱源,這樣本身也可以極大降低光互連出問題的概率。

海外一些巨頭在共封裝光學CPO上已經有一些布局。
在共封裝光學CPO上的研究,包括商業化嘗試,在過去十年一直在持續。真正做到接近量產級別的,是通訊領域的第一大巨頭博通,前面也展示了他們共封裝的交換機。今年上半年,NVIDIA在GTC上也發布了他們共封裝光學CPO產品。也就是說通信和算力界的兩大龍頭,都已經進入了這個領域。
04 基于分布式光交換的超節點新架構
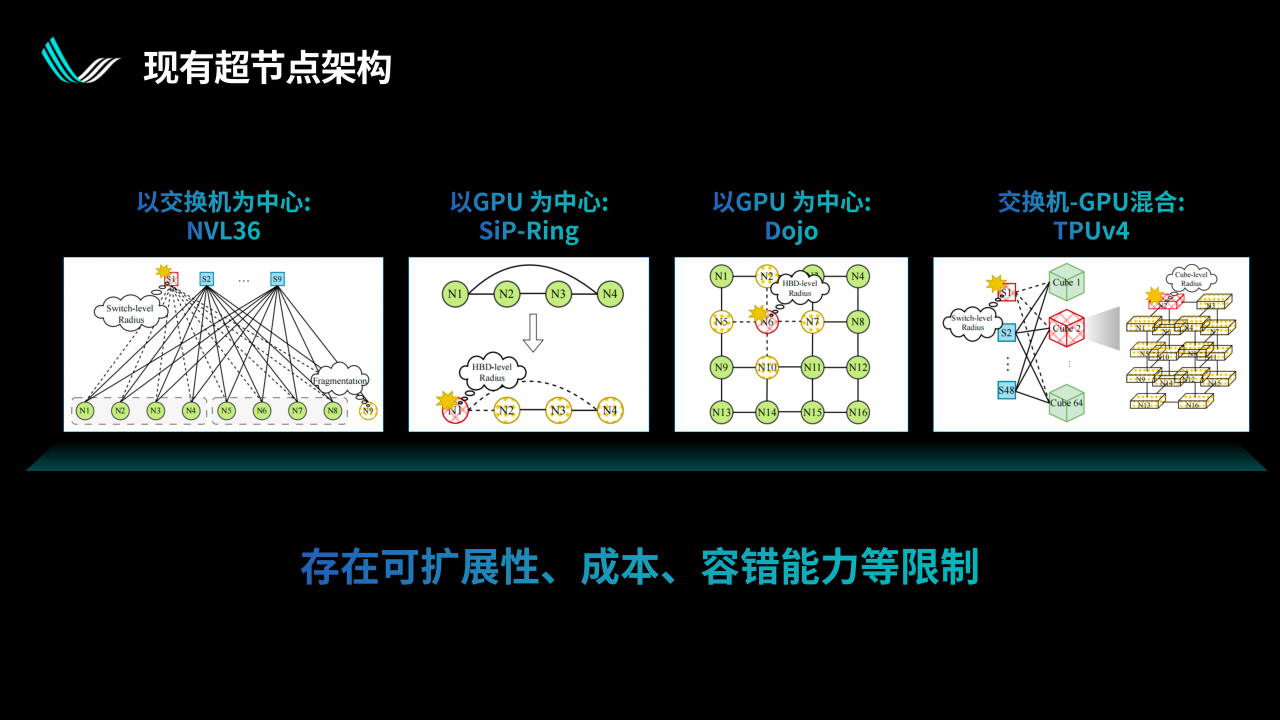
對于整體可靠性的提升,我們還有另一個想法,就是通過光交換減少冗余度。從現有超節點的架構來說,不管是直連架構,還是交換架構,都要回答一個問題:當一個超節點有上百甚至數百個GPU的時候,如何保證任何一個點出問題時,超節點還能繼續運行。所以總要有各種各樣的冗余設置在里面。

我們覺得可以把交換功能融入到光互連中,把一些小的交換功能融入到光IO領域,我們稱之為分布式光交換dOCS。這是一個很小的功能,但組成集群之后可以實現非常有意思的狀態。
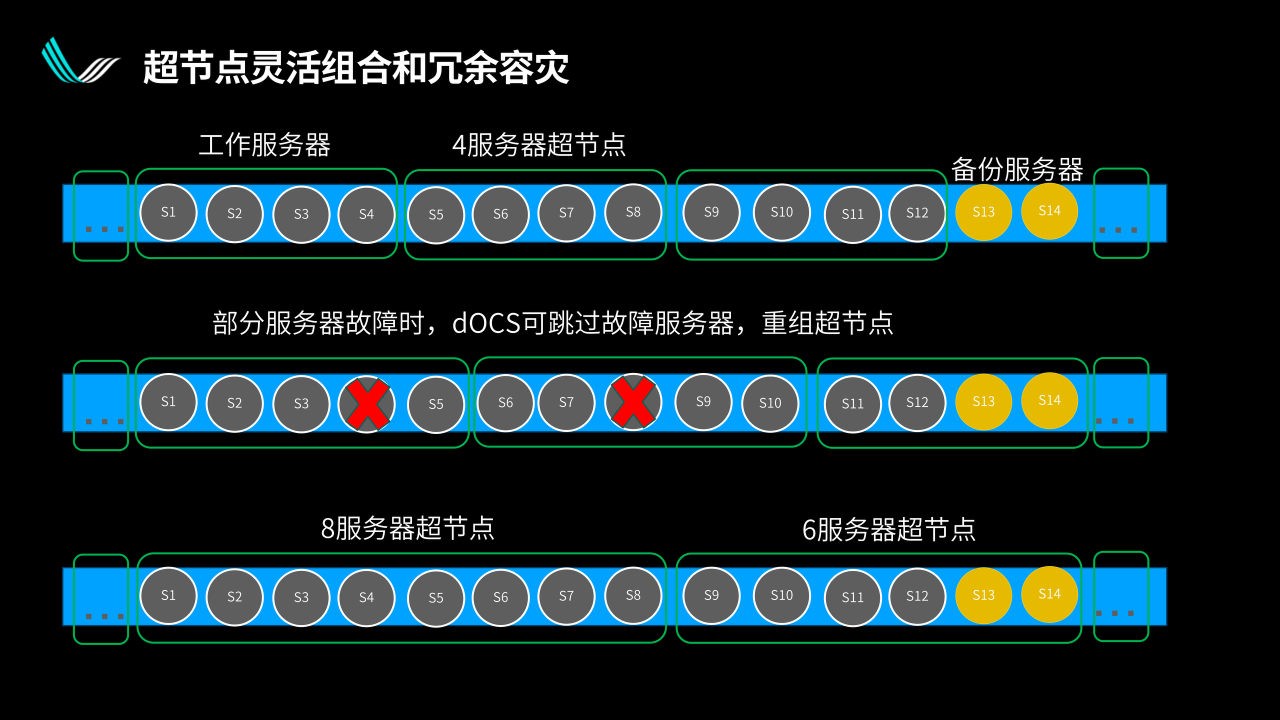
通過上圖來做一些簡單的解釋。
假設上面的每一個圓都是一個服務器,超節點是由若干個服務器組成的。正常狀態下,第一行每4個服務器(32卡)組成一個超節點,我們可以通過光互連把前面12個服務器組成三個超節點,并給到兩個備份的服務器。同時,因為我們在光互連出口的地方提供了交換功能,因此可以做靈活的拓撲切換。
假設因為某些原因兩個服務器出了問題,當系統檢測到異常時,分布式光交換可以跳過一個服務器重組超節點。比如圖中第二行,跳過第4個壞的服務器,然后把兩個備份服務器拉進來,重新把好的服務器用起來,壞的服務器下線。
這樣冗余備災的顆粒度就不是整個超節點了,只是一個服務器。對于冗余來講,能夠在很大程度上的緩解壓力,因為用來冗余備災的服務器是不再賺錢的服務器。
我們肯定希望系統在保持整個集群效率的前提下,能用更小的冗余度保證整體運營是最好的,這樣的靈活度對于大集群來說是非常有價值的。
從另一個方向來說,靈活的拓撲切換可以被用來構建不同尺寸的超節點。很多時候,超節點的尺寸并不是越高越好。
假設一個GPU出口帶寬總數一致,對于比較大的模型來說會希望組建大尺寸的超節點。但當某個時候要切換到相對小一點的模型時,比如文生圖模型比大語言模型要小很多,這種情況下,所謂最佳的超節點尺寸可能就變成了兩個服務器,或者有的時候需要六個服務器、八個服務器,可以通過靈活的切換,達到靈活改變超節點尺寸的效果。
當然把所有的服務器接上所有的交換機也可以實現,但其成本、系統的復雜度,和這樣的超節點解決方案就不在一個層次了。
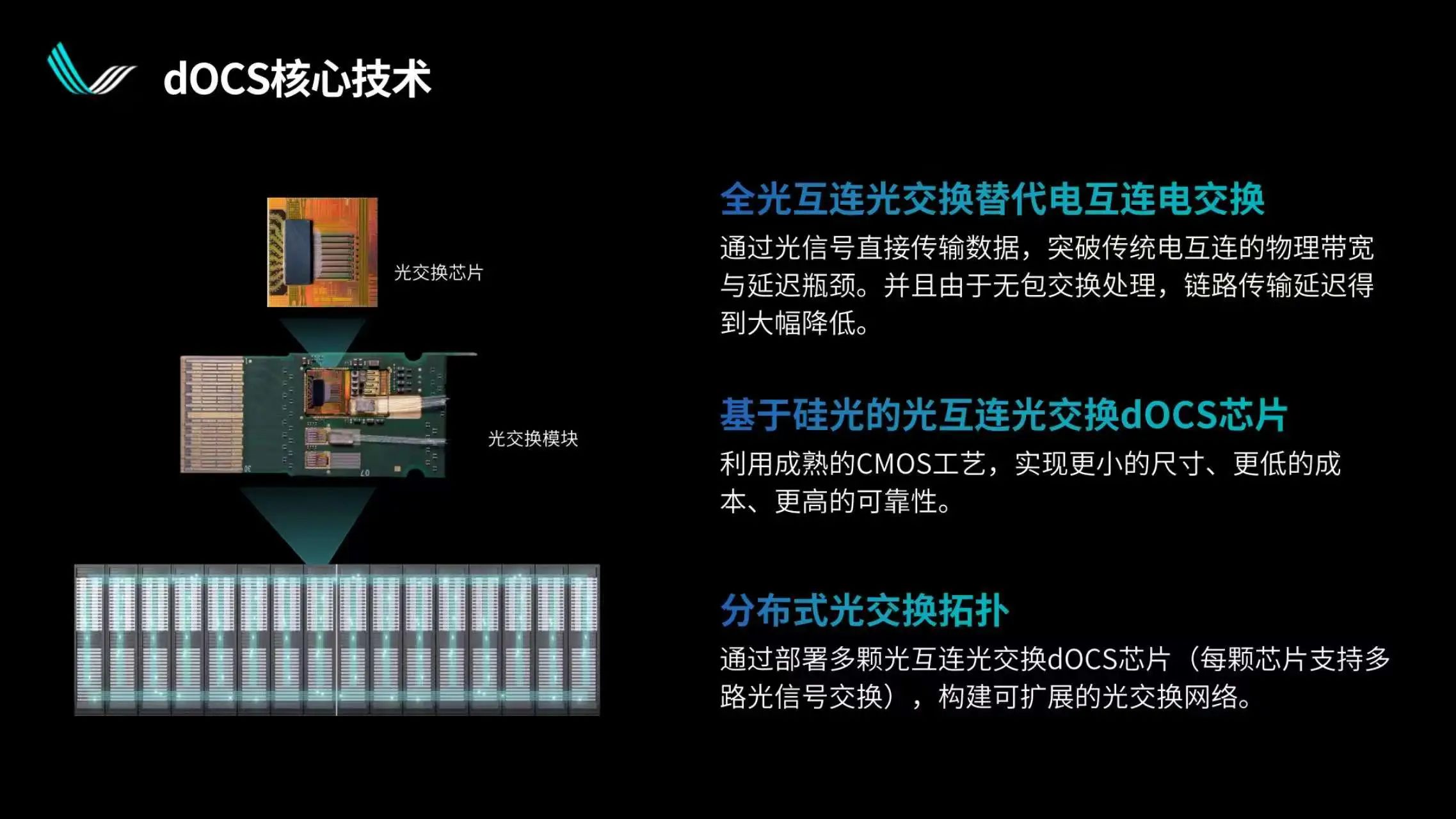
這里展示的是我們實現這一點所做的一些工作,總體來說就是集成的光電轉換。區別是我們在每一個光電轉換的出口處,做了多路徑備份,由整個系統去控制它,在恰當的時候做恰當的切換,以實現拓撲的靈活調整。

使用分布式光交換,可以在各個情況下提升超節點集群算力的利用率。此外,我們知道最大、最先進的交換芯片其實也是非常依賴先進制程和先進封裝技術的,而分布式光交換所依賴的供應鏈要簡單不少。光芯片不依賴先進制程,并且相對來說國內水平和海外差距不大,這個可能是使用光交換,尤其是分布式光交換的額外好處。
這個視頻,是曦智科技對于下一代更強大的光電混合算力集群的愿景,融入了基于純電基礎設施的優勢,同時加上集成光學可以帶來更強大的性能提升,共同組成一個包括光電混合計算+光互連+光交換的集群狀態。
本文地址:http://www.welmoon.com//Site/CN/News/2025/08/07/20250807110609308808.htm 轉載請保留文章出處
關鍵字:
文章標題:光互連與光交換解鎖超節點規模上限|曦智科技CTO孟懷宇博士報告回顧
2、免責聲明,凡本網注明“來源:XXX(非訊石光通訊網)”的作品,均為轉載自其它媒體,轉載目的在于傳遞更多信息,并不代表本網贊同其觀點和對其真實性負責。因可能存在第三方轉載無法確定原網地址,若作品內容、版權爭議和其它問題,請聯系本網,將第一時間刪除。
聯系方式:訊石光通訊網新聞中心 電話:0755-82960080-168 Right
- · 光電共封裝(CPO):數據中心網絡和處理技術的未來
- · Tower財報會議:硅光量產提速5倍 1.6T接收端革命
- · 光特科技發布背照式200G PD光芯片 助力AI智算光網高效互聯
- · LC:AI集群推動光模塊市場爆發 2025年增速超30%
- · Yole:AI重塑數據中心 2030年半導體價值或達5000億美元
- · LightCounting:CPO開發達頂峰,2027年迎量產
- · CUBE-Net 2025研討:可插拔與CPO的混合部署已成為產業共識
- · 光圣拿下馬來西亞數據中心大單 7月出貨推動股價漲停
- · 阻礙CPO產業化落地的挑戰有哪些?8月8日CUBE-Net 2025大會上即時研討
- · 邁向光纖到芯片技術的飛躍——釋放光電共封裝(CPO)和玻璃波導基板的潛力
- 設置首頁 | 光通訊招聘 | 企業搜索庫 | 廣告服務 | 聯系我們 | 保護私隱 | 公司介紹
Copyright ? 2009 ICCSZ.com Inc. All Rights Reserved. 訊石公司 www.welmoon.com版權所有 粵ICP備12008183號-1